Elasticsearch 系列
內容 連結 Elasticsearch 基礎操作 https://blog.yexca.net/zh-tw/archives/226 Elasticsearch 查詢操作 https://blog.yexca.net/zh-tw/archives/227 RestClient 基礎操作 https://blog.yexca.net/zh-tw/archives/228 RestClient 查詢操作 https://blog.yexca.net/zh-tw/archives/229 Elasticsearch 資料聚合 https://blog.yexca.net/zh-tw/archives/231 Elasticsearch 自動補齊 https://blog.yexca.net/zh-tw/archives/232 Elasticsearch 資料同步 https://blog.yexca.net/zh-tw/archives/234 Elasticsearch 叢集 本文
單機的 ES 用於資料儲存勢必面臨兩個問題:海量資料儲存與單點故障問題
- 海量資料儲存問題:將索引庫從邏輯上拆分為 N 個分片 (shard),儲存到多個節點
- 單點故障問題:將分片資料在不同節點備份 (replica)
ES 叢集相關概念
- 叢集 (cluster):一組擁有共同 cluster name 的節點
- 節點 (node):叢集中的一個 ES 實例
- 分片 (shard):索引可以被拆分為不同的部分進行儲存,稱為分片。在叢集環境下,一個索引的不同分片可以拆分到不同的節點中
解決問題:資料量太大,單點儲存量有限的問題
分片類似 Hadoop 的 HDFS,其資料會分成多份備份
- 主分片 (Primary shard):相對於副本分片的定義
- 副本分片 (Replica shard):每個主分片可以有一個或多個副本,資料與主分片相同
建置 ES 叢集
可以透過 docker-compose 來完成
| |
ES 運行需要修改一些 Linux 系統權限,請修改 /etc/sysctl.conf 檔案
| |
請新增以下內容:
| |
接著執行指令,讓配置生效:
| |
透過 docker-compose 啟動叢集:
| |
監控叢集狀態
Kibana 可以監控 ES 叢集,不過需要依賴 ES 的 X-Pack 功能,設定相對複雜
可以使用 Cerebro 來監控 ES 叢集,GitHub: https://github.com/lmenezes/cerebro
執行 bin/cerebro.bat 後,即可前往
http://localhost:9000
進入管理介面
使用 Cerebro 可以視覺化建立索引庫,以下是 DSL 語法建立
| |
叢集職責劃分
ES 中,叢集節點有不同的職責劃分
| 節點類型 | 配置參數 | 預設值 | 節點職責 |
|---|---|---|---|
| Master eligible | node.master | true | 候選主節點:主節點可以管理和記錄叢集狀態、決定分片在哪個節點、處理建立和刪除索引庫的請求 |
| Data | node.data | true | 資料節點:儲存資料、搜尋、聚合、CRUD |
| Ingest | node.ingest | true | 資料儲存之前的預處理 |
| Coordinating | 上面 3 個參數都為 false 則為 Coordinating 節點 | 無 | 將請求路由到其他節點,合併其他節點處理的結果,並回傳給使用者 |
預設情況下,叢集的任何一個節點都同時具備上述四種角色
但真實的叢集一定要將叢集職責分離
- Master 節點:對 CPU 要求高,但是記憶體要求低
- Data 節點:對 CPU 和記憶體要求都高
- Coordinating 節點:對網路頻寬、CPU 要求高
職責分離可以讓我們根據不同節點的需求分配不同的硬體去部署。而且能避免業務之間的相互干擾
叢集腦裂問題
腦裂是因為叢集中的節點失聯所導致的
假設有三個節點,現在主節點 (node1) 與其他節點失聯 (網路阻塞),node2 和 node3 會認為 node1 宕機,就會重新選主。假設 node3 當選,叢集會繼續對外提供服務,node2 和 node3 自成叢集,node1 自成叢集,這兩個叢集資料不同步,因而出現資料差異
當網路阻塞恢復正常,由於叢集中有兩個 Master 節點,叢集狀態不一致,於是出現腦裂的情況
解決方案:要求選票超過 (eligible 節點數量 + 1) / 2 才能當選為 Master 節點,因此 eligible 節點數量最好是奇數。對應的配置項為 discovery.zen.minimum_master_nodes,在 ES 7.0 之後,這已成為預設配置,因此一般不會發生腦裂問題
例如上述 3 個節點形成的叢集,選票必須超過 (3+1)/2 = 2 票。node3 得到 node2 和 node3 的選票,當選為主,而 node1 只有自己的一票,沒有當選。叢集中依然只有 1 個主節點,沒有出現腦裂
叢集分散式儲存
當新增文件時,應該保存到不同分片,確保資料平衡,那麼 Coordinating 節點如何確定資料該儲存到哪個分片呢
ES 會透過 Hash 演算法來計算文件應該儲存到哪個分片
公式:shard = hash(_routing) % number_of_shards
說明:
- _routing 預設是文件的 ID
- 演算法與分片數量有關,因此索引庫一旦建立,分片數量就不能修改
新增文件流程:
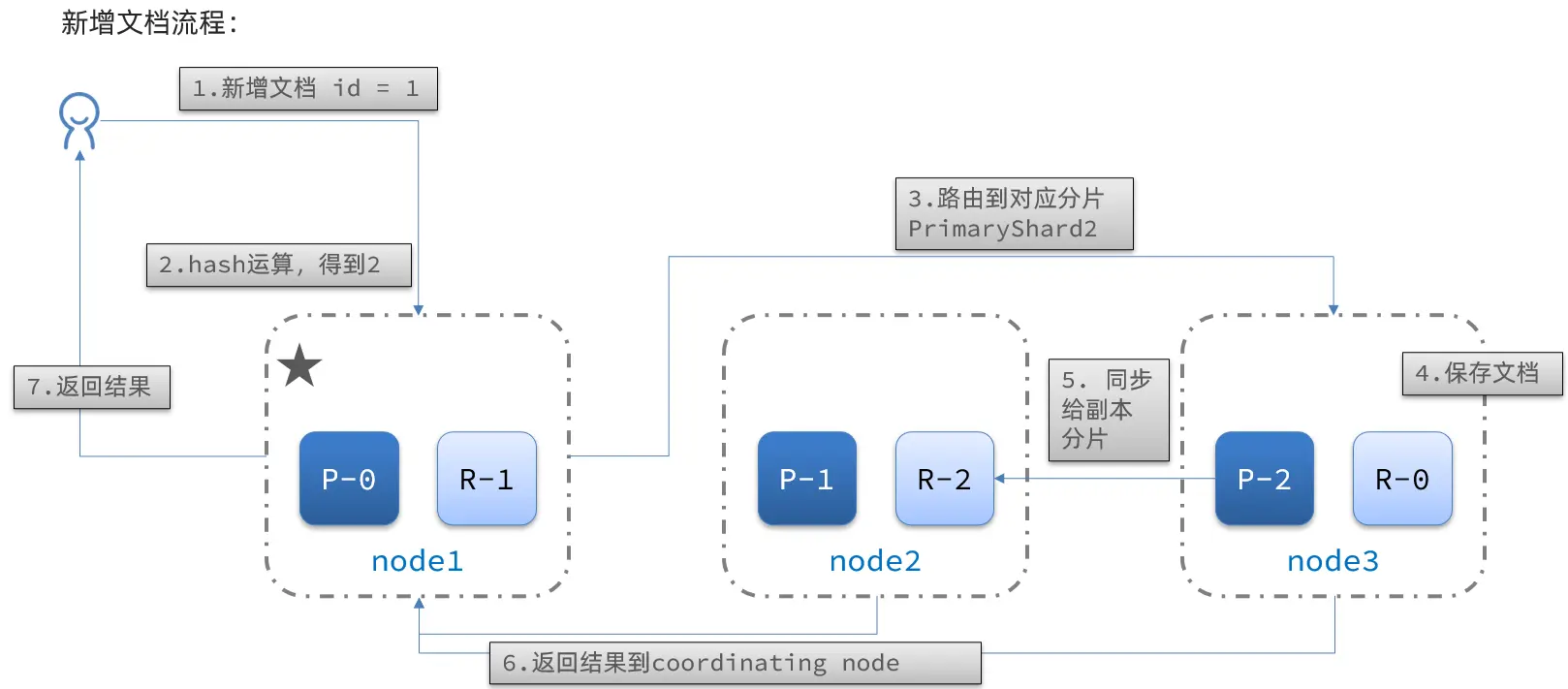
流程:
- 新增一個 ID = 1 的文件
- 對 ID 執行 Hash 運算,假如得到的是 2,則對應儲存到 shard-2
- shard-2 的主分片在 node3 節點,將資料路由到 node3
- 保存文件
- 同步給 shard-2 的副本 replica-2,在 node2 節點
- 回傳結果給 Coordinating 節點
叢集分散式查詢
ES 的查詢分為兩個階段:
- Scatter Phase:分散階段,Coordinating 節點會把請求分發到每一個分片
- Gather Phase:聚集階段,Coordinating 節點會彙總 Data 節點的搜尋結果,並處理成最終結果集回傳給使用者
叢集容錯移轉
叢集的 Master 節點會監控叢集中的節點狀態,如果發現有節點宕機,會立即將宕機節點的分片資料遷移到其他節點,確保資料安全,這稱為容錯移轉
假設一個叢集有三個節點,node1 是主節點
- node1 發生了宕機
- 需要重新選主,假設選中了 node2
- node2 成為主節點後,會檢測叢集狀態,發現 node1 的分片沒有副本節點,需要將 node1 上的資料遷移到 node2、node3