この記事は Hiyoung が書いたよ。
1. SQL ORDER BY キーワード
ORDER BY キーワードは、結果セットを1つまたは複数の列でソートするために使うんだ。
ORDER BY キーワードはデフォルトで昇順(小さい順)にレコードを並べ替えるよ。もし降順(大きい順)にしたいなら、DESC キーワードを使えばOK。
SQL ORDER BY の構文
| |
– ASC は昇順、DESC は降順を意味するよ。
– ORDER BY 文を使うときは、すべての文の最後に置くのがルール。複数の列でソートするときは、まず column\_name1 で並べ替えて、その次に column\_name2… という順序で処理されるよ。
2. すべてのデータを削除する(DELETE と DROP TABLE)
テーブル自体を削除せずに、テーブル内のすべての行だけを削除することができるよ。これなら、テーブルの構造、属性、インデックスはそのまま残るんだ。
DELETE FROM table\_name;
または
DELETE * FROM table\_name;
注意: レコードを削除するときはマジで気をつけて!やり直しはきかないからね!
DROP TABLE 文
DROP TABLE 文はテーブルそのものを削除するために使うよ。
DROP TABLE table\_name
注意: DELETE と違うのは、DROP TABLE はテーブルのデータも構造も丸ごと削除しちゃうこと。これも後戻りできない操作だよ!
DROP DATABASE 文
DROP DATABASE 文はデータベースを削除するために使うんだ。
DROP DATABASE database\_name
TRUNCATE TABLE 文
もしテーブル内のデータだけを削除したくて、テーブル自体は残しておきたい場合はどうすればいいかな?
そんなときは TRUNCATE TABLE 文を使おう。
TRUNCATE TABLE table\_name
3. SQL JOIN
SQL の JOIN は、2つ以上のテーブルの行を組み合わせるために使われるよ。
下の図は、LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN に関連する 7 種類の使い方を示しているんだ。
- INNER JOIN:テーブル間に少なくとも1つのマッチがあれば行を返す(INNER JOIN と JOIN は同じ意味だよ)
- LEFT JOIN:右のテーブルにマッチするものがなくても、左のテーブルのすべての行を返す
- RIGHT JOIN:左のテーブルにマッチするものがなくても、右のテーブルのすべての行を返す
- FULL JOIN:どちらかのテーブルにマッチがあれば行を返す
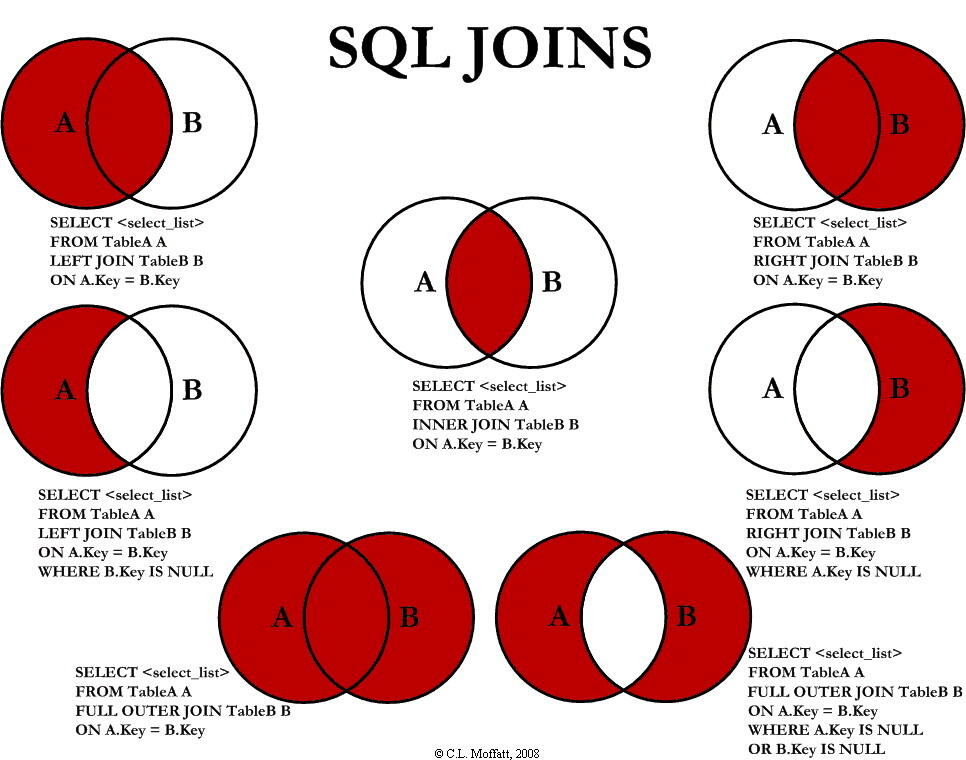
注意:SQL の JOIN 文は、実はデータベース理論における「結合」の概念に対応しているんだ。LEFT JOIN、RIGHT JOIN、INNER JOIN は自然結合に、FULL JOIN はデカルト積に対応しているよ。
4. SQL 制約 (Constraints)
| |
- NOT NULL – その列に NULL 値を保存できないようにする。
- UNIQUE – その列の各行が必ず一意(ユニーク)な値であることを保証する。(1つのテーブルに複数の UNIQUE 制約を設定できるけど、PRIMARY KEY は1つだけ。PRIMARY KEY には自動的に UNIQUE 制約が含まれるよ)
- PRIMARY KEY – NOT NULL と UNIQUE を組み合わせたもの。その列(または複数列の組み合わせ)に一意の識別子を持たせ、特定のレコードを素早く簡単に見つけられるようにするんだ。(主キー)
- FOREIGN KEY – あるテーブルのデータが別のテーブルの値と一致することを保証し、参照整合性を守るためのもの。(外部キー)
- CHECK – 列の値が指定された条件を満たしているか確認する。
- DEFAULT – 列に値が指定されなかったときのデフォルト値を決めておく。
5. AUTO INCREMENT フィールド
新しいレコードを挿入するたびに、主キーの値を自動的に生成したいことってよくあるよね。
そんなときは、テーブルに auto-increment フィールドを作成すればいいんだ。
次の SQL 文は、“Persons” テーブルの “ID” 列を auto-increment の主キーとして定義しているよ。
| |
上の例では、IDENTITY の開始値は 1 で、新しいレコードが追加されるたびに 1 ずつ増えていく設定になっているよ。
ヒント: もし “ID” 列を 10 から始めて 5 ずつ増やしたいなら、IDENTITY を IDENTITY(10,5) に変えれば OK。
“Persons” テーブルに新しいレコードを挿入するとき、“ID” 列に値を指定する必要はないよ(自動的にユニークな値が割り振られるからね)。
| |
この SQL 文を実行すると、“Persons” テーブルに新しいレコードが挿入され、“ID” 列には自動で値が入り、“FirstName” は ‘Lars’、“LastName” は ‘Monsen’ に設定されるんだ。