Elasticsearch シリーズ
内容 リンク Elasticsearch 基本操作 https://blog.yexca.net/ja/archives/226 Elasticsearch 検索操作 https://blog.yexca.net/ja/archives/227 RestClient 基本操作 https://blog.yexca.net/ja/archives/228 RestClient 検索操作 https://blog.yexca.net/ja/archives/229 Elasticsearch データ集約 https://blog.yexca.net/ja/archives/231 Elasticsearch オートコンプリート https://blog.yexca.net/ja/archives/232 Elasticsearch データ同期 https://blog.yexca.net/ja/archives/234 Elasticsearch クラスター この記事
ESを単体でデータ保存に使うと、どうしても二つの問題に直面するんだ。大量のデータ保存と単一障害点の問題だね。
- 大量データ保存の問題:インデックスを論理的にN個のシャードに分割して、複数のノードに保存する。
- 単一障害点の問題:シャードデータを異なるノードにバックアップ(レプリカ)する。
ESクラスター関連の概念
- クラスター (cluster):共通のクラスター名を持つノードのグループのこと。
- ノード (node):クラスター内のESインスタンスの一つだよ。
- シャード (shard):インデックスは異なる部分に分割して保存できるんだ。これをシャードと呼ぶよ。クラスター環境では、一つのインデックスの異なるシャードを別々のノードに分割して保存できるんだ。
解決する問題:データ量が多すぎたり、単一ノードの保存量が限られている問題。
シャードはHadoopのHDFSでデータを複数に分けてバックアップするのに似てるね。
- プライマリシャード (Primary shard):レプリカシャードとの対比で定義されるよ。
- レプリカシャード (Replica shard):各プライマリシャードは一つ以上のレプリカを持つことができて、データはプライマリシャードと同じなんだ。
ESクラスターの構築
docker-composeを使えばできるよ。
| |
ESを動かすにはLinuxのシステム権限をいくつか変更する必要があるんだ。/etc/sysctl.conf ファイルを編集するよ。
| |
以下の内容を追加してね:
| |
それから、コマンドを実行して設定を有効にするんだ:
| |
docker-composeでクラスターを起動するよ:
| |
クラスターの状態監視
KibanaでもESクラスターを監視できるけど、ESのX-Pack機能に依存するから設定がちょっと複雑なんだ。
Cerebroを使ってESクラスターを監視することもできるよ。Githubはこちら: https://github.com/lmenezes/cerebro
bin/cerebro.bat を実行したら
http://localhost:9000
にアクセスするだけで管理画面に入れるよ。
Cerebroを使えばインデックスを視覚的に作成できるんだ。以下はDSLステートメントでの作成例だよ。
| |
クラスターの役割分担
ESのクラスターノードには異なる役割があるんだ。
| ノードタイプ | 設定パラメータ | デフォルト値 | ノードの役割 |
|---|---|---|---|
| マスター適格 | node.master | true | 候補マスターノード:マスターノードはクラスターの状態を管理・記録したり、シャードがどのノードにあるかを決めたり、インデックスの作成・削除リクエストを処理したりできるよ。 |
| データ | node.data | true | データノード:データを保存したり、検索、集約、CRUDを行うんだ。 |
| インジェスト | node.ingest | true | データ保存前の前処理をするんだ。 |
| コーディネーティング | 上記3つのパラメータが全てfalseだとコーディネーティングノードになるよ。 | なし | 他のノードへリクエストをルーティングしたり、他のノードが処理した結果を結合してユーザーに返すんだ。 |
デフォルトだと、クラスターのどのノードも上記の4つの役割を同時に持ってるんだ。
でも、実際のクラスターではクラスターの役割を分ける必要があるんだ。
- マスターノード:CPUの要求は高いけど、メモリの要求は低いよ。
- データノード:CPUもメモリも要求が高いんだ。
- コーディネーティングノード:ネットワーク帯域幅やCPUの要求が高いよ。
役割を分離することで、異なるノードの要求に合わせて異なるハードウェアを割り当ててデプロイできるんだ。それに、業務間の相互干渉も防げるよ。
クラスターの脳裂問題
脳裂はクラスター内のノードが連絡を失うことで発生するんだ。
3つのノードがあると仮定して、マスターノード (node1) が他のノードと通信できなくなった(ネットワークが遮断された)とするね。node2とnode3はnode1がダウンしたと判断して、新しいマスターを選出し直すんだ。もしnode3が選出されたら、クラスターは外部にサービスを提供し続けるけど、node2とnode3は独自のクラスターになり、node1も独自のクラスターになってしまう。2つのクラスター間でデータが同期されず、データの差異が生じることになるんだ。
ネットワークの遮断が正常に戻ると、クラスター内にマスターノードが2つできてしまうから、クラスターの状態が不一致になり、脳裂状態が発生するんだ。
解決策:マスターノードに選出されるには、投票数が (適格ノード数 + 1) / 2 を超える必要があるんだ。だから、適格ノード数は奇数であるのがベストだよ。対応する設定項目は discovery.zen.minimum_master_nodes で、ES 7.0以降ではこれがデフォルト設定になってるから、通常は脳裂問題は発生しないんだ。
例えば、上記の3つのノードで構成されたクラスターだと、投票数は (3+1)/2 = 2票を超える必要があるんだ。node3はnode2とnode3の投票を得てマスターに選出されるけど、node1は自分の一票しか得られないから選出されない。クラスター内には引き続き1つのマスターノードしか存在せず、脳裂は発生しないってわけだね。
クラスターの分散ストレージ
新しいドキュメントを追加するときは、データが均等に分散されるように異なるシャードに保存するべきなんだけど、コーディネーティングノードはどうやってデータをどのシャードに保存するか決めるんだろうね?
ESはハッシュアルゴリズムを使って、ドキュメントがどのシャードに保存されるべきかを計算するんだ。
公式:shard = hash(_routing) % number_of_shards
説明:
_routingはデフォルトでドキュメントのIDなんだ。- アルゴリズムはシャード数に関係してるから、インデックスが一度作成されたらシャード数は変更できないんだ。
ドキュメント追加のフロー:
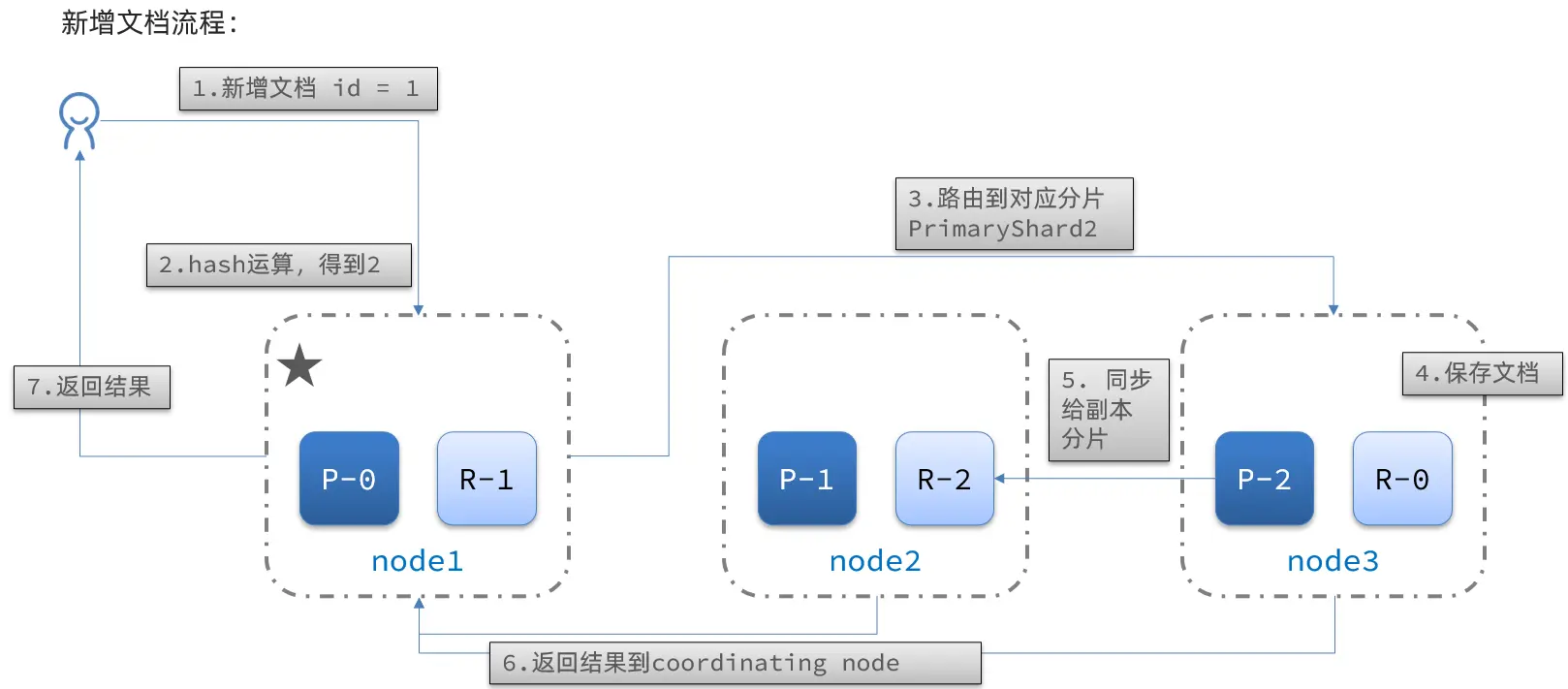
フロー:
- IDが1のドキュメントを新規追加する。
- IDに対してハッシュ計算を行い、もし2が得られたらshard-2に対応して保存するんだ。
- shard-2のプライマリシャードはnode3ノードにあるから、データをnode3にルーティングするよ。
- ドキュメントを保存する。
- shard-2のレプリカreplica-2(node2ノードにある)に同期する。
- coordinating-nodeノードに結果を返す。
クラスターの分散クエリ
ESのクエリは2つのフェーズに分かれているよ:
- scatter phase:分散フェーズで、coordinating nodeがリクエストを各シャードに分配するんだ。
- gather phase:集約フェーズで、coordinating nodeがデータノードの検索結果をまとめて、最終的な結果セットとしてユーザーに返すよ。
クラスターのフェイルオーバー
クラスターのマスターノードはクラスター内のノードの状態を監視していて、もしノードがダウンしたのを見つけたら、すぐにダウンしたノードのシャードデータを他のノードに移行させて、データの安全を確保するんだ。これをフェイルオーバーと呼ぶよ。
クラスターに3つのノードがあって、node1がマスターノードだと仮定するね。
- node1がダウンしたとしよう。
- 新しいマスターを選出し直す必要があるね。node2が選ばれたと仮定するよ。
- node2がマスターノードになったら、クラスターの状態をチェックして、node1のシャードにレプリカノードがないことに気づくんだ。それで、node1上のデータをnode2、node3に移行させる必要があるってことになるよ。